Day 5 - when we investigated the problem of similarity search
State of the Art
Search engines already existed in the 2010 with technology such as Lucene and Elasticsearch, for text-based search. The problem of similarity search, for numerical vector-based search, then came up, and large companies found out it brought great user experiences. This new technique, in fact, allowed spotting similar patterns and revealing connections between the contents.
In 2015, Spotify was one of the first large Internet companies to use these algorithms in production, when Erik Bernhardsson open sourced spotify/annoy.
In 2017, Facebook then released facebookresearch/faiss to enable searching multimedia documents that are similar to each other, indexing a record of billions of documents using GPU
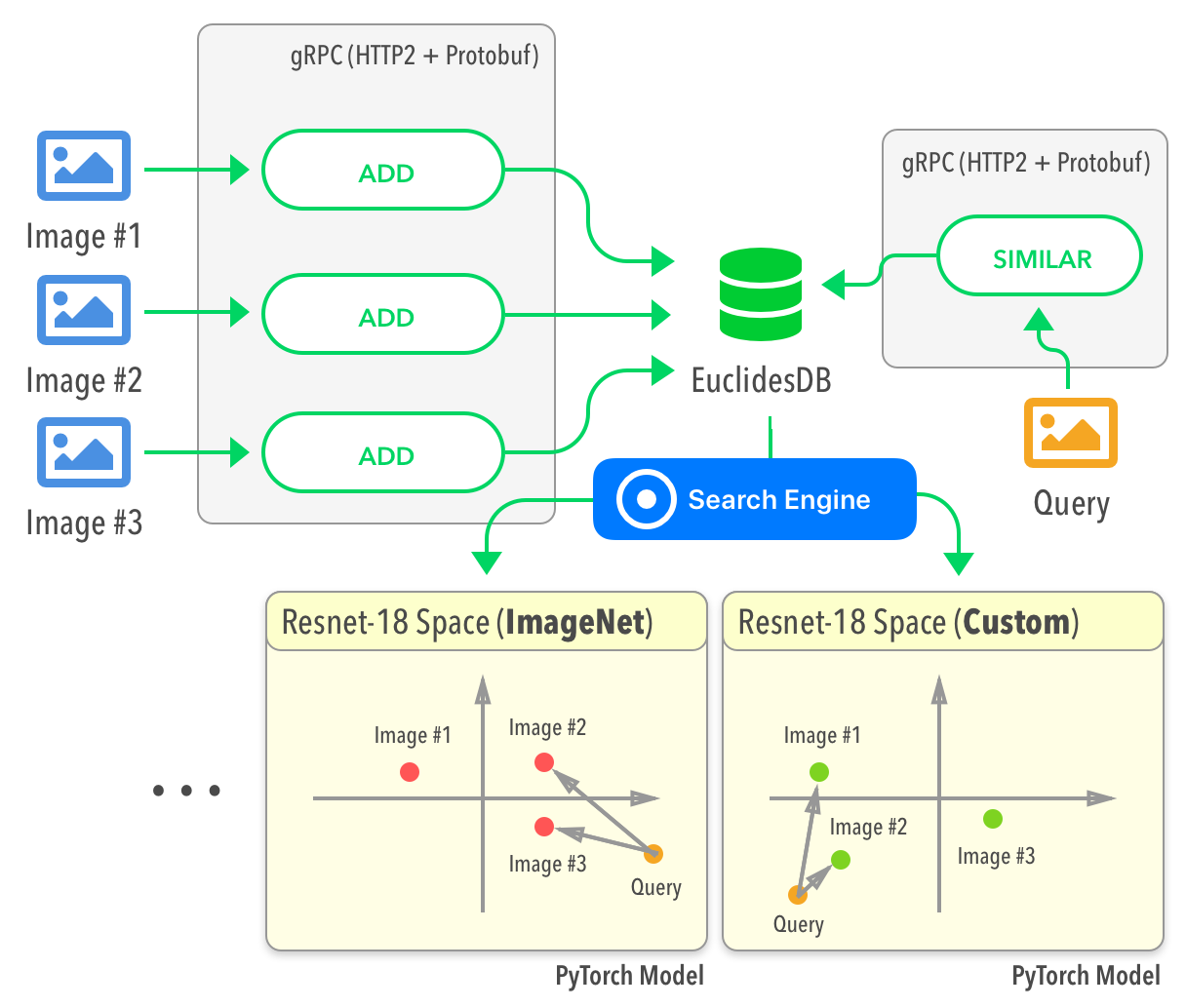
Other open source projects such as perone/euclidesdb then enabled developers to use the embeddings comparison concepts to be hosted on a database.
Then, BERT models began to outperform most of the models, introducing a new era for NLP. In 2020, GCP also proposed a similarity search experience using Apache Beam and Annoy, which later moved to VertexAI.
HuggingFace and OpenAI then largely disrupted access to deep learning models and made embeddings easier to use than ever. Having a good machine learning model that turns sentences into a vector representation is indeed essential in the process.
Redis Vector Similarity Search
Redis Vector Similarity Search (VSS) is an extension in the continuity of the previous works, it allows users already familiar with Redis to perform vector similarity queries using the FT.SEARCH command.
Developers can easily load, index, and query vectors, and these vectors come from a variety of unstructured data.
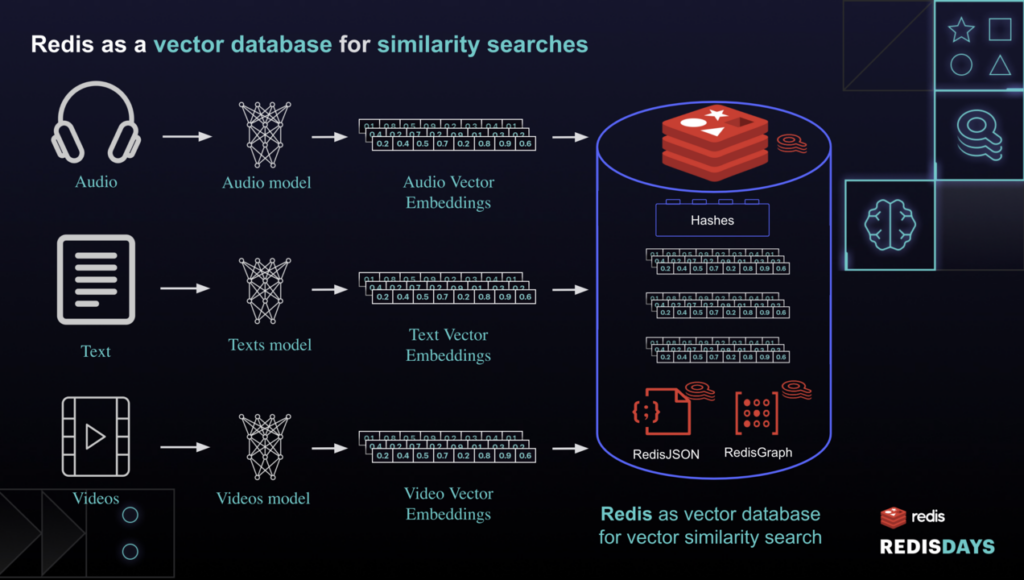
Using Hashes, RediSearch is capable of maintaining two types of indexing FLAT, which is a naive indexing method, and HNSW (Hierarchical Navigable Small World) which is derived from earlier Facebook's work. Distance metrics include Euclidean distance L2, Internal product IP and Cosine distance COSINE, which are common ways to evaluate how close vectors are to each other.
All this process can happen in real time, meaning you can write or update indexes to RediSearch anytime you want while serving requests to your users.
To store embeddings in Redis Hashes, you have to encode the vector data in binary mode, like that was the case in the demo code. Another alternative is to store it in clear text, and this might be more convenient.
The space of embeddings can be searched using two methods, KNN (k Nearest neighbours) and VECTOR_RANGE. The demo was about using KNN, but studying the difference between the two can help. The Redis documentation could provide more examples for this, as it is hard to find what to choose in which situations.
Using these different algorithms, Redis can then return the top 100 most semantically similar sentences across millions of documents, ordered by increasing vector distance.
RediSearch is a piece of technology that bridges the gap between data science teams who know how to build models, and production environments thus allowing data science and data engineering teams to work together on the same platform.
It also provides a real-time endpoint where users can formulate live queries and retrieve the most relevant documents.
References
State of the Art of Similarity Search
- Erik Bernahardsson - Approximate nearest neighbors & vector models
- Faiss: A library for efficient similarity search
- GCP - Building a real-time embeddings similarity matching system
- Vertex AI - Matching Engine ANN service overview